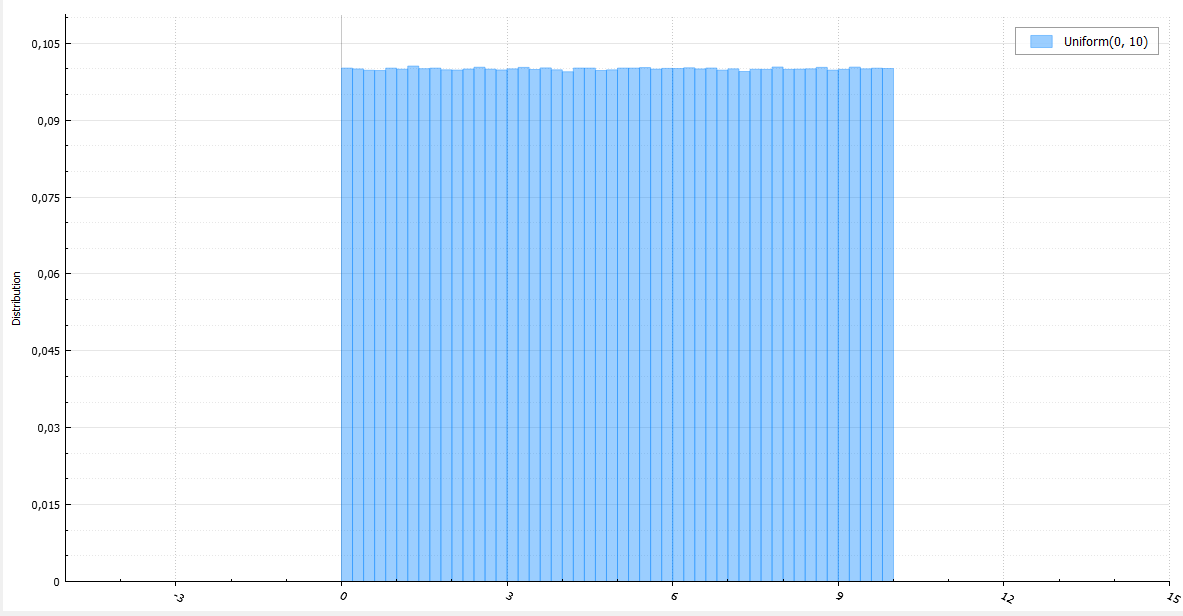
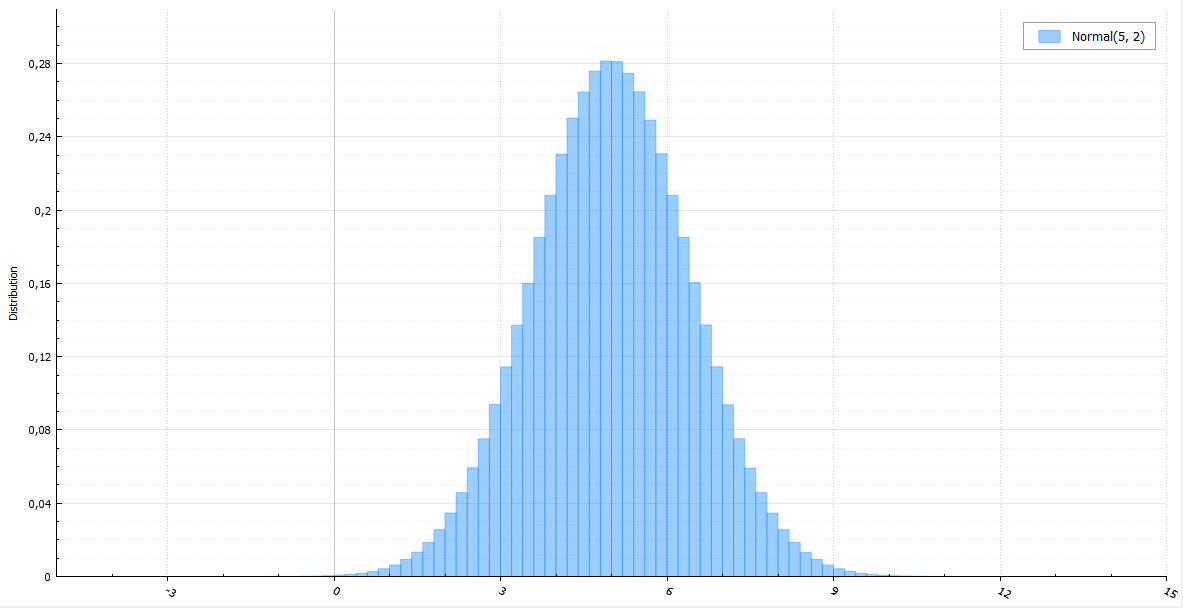
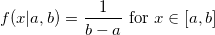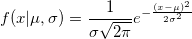Введение в хеш-таблицы
Хеш-таблица представляет собой обобщение обычного массива. Однако в то время как ключом массива может быть только число, для хеш-таблицы им может быть любой объект, для которого можно вычислить хеш-код. Но об этом позже. Итак, интерфейс хеш-таблицы предоставляет нам следующие операции:
- Добавление новой пары ключ-значение
- Поиск значения по ключу
- Удаление пары ключ-значение по ключу
Среднее время поиска значения по ключу в хеш-таблице равно O(1). Это значит, что в среднем, наш поиск не будет зависеть от количества элементов в хеш-таблице, и будет равен некоторому константному значению. В зависимости от самой внутренней реализации хеш-таблицы, время поиска для наихудшего случая может быть O(n), то есть линейно завесить от количества элементов в таблице, либо же оставаться O(1).
Что же такое хеширование? Идея хеширования основана на распределении ключей в обычном массиве H[0..m-1]. Распределение осуществляется вычислением для каждого ключа элемента некоторой хеш-функции h. Эта функция на основе ключа вычисляет целое число n, которое служит индексом для массива H. Конечно, необходимо придумать такую хеш-функцию, которая бы давала различный хеш-код для различных объектов.
Коллизии

Этот рисунок иллюстрирует одну из основных проблем. При достаточно маленьком значении m (размера хеш-таблицы) по отношению к n (количеству ключей) или при плохой хеш-функции, может случиться так, что два ключа будут хешированны в одну и ту же ячейку массива H. Такая ситуация называется коллизией. Хорошие хеш-функции стремятся минимизировать вероятность коллизий, однако, учитывая то, что пространство всех возможных ключей может быть больше размера нашей хеш-таблицы H, всё же избежать их вряд ли удастся. На этот случай имеются несколько технологий для разрешения коллизий. Основные из них мы и рассмотрим далее.
Хеширование с цепочками
В случае открытого хеширования (другое название хеширования цепочками), мы объедением элементы, хешированные в одну и ту же ячейку, в связный список.
Если при добавлении в хеш-таблицу в заданную ячейку мы встречаем ссылку на элемент связного списка, то случается коллизия. Так, мы просто вставляем наш элемент как узел в список. При поиске мы проходим по цепочкам, сравнивая ключи между собой на эквивалентность, пока не доберёмся до нужного. При удалении ситуация такая же.
Процедура вставки выполняется даже в наихудшем случае за O(1), учитывая то, что мы предполагаем отсутствие вставляемого элемента в таблице. Время поиска зависит от длины списка, и в худшем случае равно O(n). Эта ситуация, когда все элементы хешируются в единственную ячейку. Если функция распределяем n ключей по m ячейкам таблицы равномерно, то в каждом списке будет содержаться порядка n/m ключей. Это число называется коэффициентом заполнения хеш-таблицы. Математический анализ хеширования с цепочками показывает, что в среднем случае все операции в такой хеш-таблице в среднем выполняются за время O(1).
Хеширование с открытой адресацией
В случае метода открытой адресации (или по-другому: закрытого хеширования) все элементы хранятся непосредственно в хеш-таблице, без использования связанных списков. В отличии от хеширования с цепочками, при использовании метода открытой адресации может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, так что будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
Для разрешения же коллизий применяются несколько подходов. Самый простой из них – это метод линейного исследования. В этом случае при возникновении коллизии следующие за текущей ячейки проверяются одна за другой, пока не найдётся пустая ячейка, куда и помещается наш элемент. Так, при достижении последнего индекса таблицы, мы перескакиваем в начало, рассматривая её как «цикличный» массив.
Линейное хеширование достаточно просто реализуется, однако с ним связана существенная проблема – кластеризация. Это явление создания длинных последовательностей занятых ячеек, которое увеличивает среднее время поиска в таблице. Для снижения эффекта кластеризации используется другая стратегия разрешения коллизий – двойное хеширование. Основная идея заключается в том, что для определения шага смещения исследований при коллизии в ячейке используется другая хеш-функция, вместо линейного смещения на одну позицию.
Одной из сложных вопросов реализации хеширования с открытой адресацией – это операция удаления элемента. Дело в том, что если мы просто удалим некий элемент их хеш-таблицы, то сделаем невозможным поиск ключа, в процессе вставки которого текущая ячейка оказалась заполненной. Так, мы можем помечать очищенные ячейки какой-то меткой, чтобы впоследствии это учитывать.
 значение
значение  называется значением, ассоциированным с ключом
называется значением, ассоциированным с ключом  . Семантика и названия вышеупомянутых операций в разных реализациях ассоциативного массива могут отличаться.
. Семантика и названия вышеупомянутых операций в разных реализациях ассоциативного массива могут отличаться. , где
, где  — текущее количество хранимых пар. Для сбалансированных деревьев поиска (в том числе для красно-чёрных деревьев) это условие выполнено.
— текущее количество хранимых пар. Для сбалансированных деревьев поиска (в том числе для красно-чёрных деревьев) это условие выполнено. , что лучше, чем в реализациях, основанных на деревьях поиска. Но при этом не гарантируется высокая скорость выполнения отдельной операции: время операции INSERT в худшем случае оценивается как
, что лучше, чем в реализациях, основанных на деревьях поиска. Но при этом не гарантируется высокая скорость выполнения отдельной операции: время операции INSERT в худшем случае оценивается как  . Операция INSERT выполняется долго, когда коэффициент заполнения становится высоким и необходимо перестроить индекс хэш-таблицы.
. Операция INSERT выполняется долго, когда коэффициент заполнения становится высоким и необходимо перестроить индекс хэш-таблицы.